URL Discovery Tools: Best Options for Faster Indexing in 2026

TL;DR
URL discovery tools help search engines, crawlers, and AI systems find pages before ranking or citation can happen. The strongest 2026 setup combines clean internal links, fresh XML sitemaps, feed-based updates, crawl auditing, and selective automation through indexing platforms.
URL discovery tools: software, feeds, files, and workflows that expose new or changed URLs to crawlers before indexing begins. For large sites, discovery is no longer a one-time sitemap task; it affects Google visibility, AI answer inclusion, and content operations. Indexerhub fits this workflow by helping teams manage discovery signals at scale.
Table of Contents
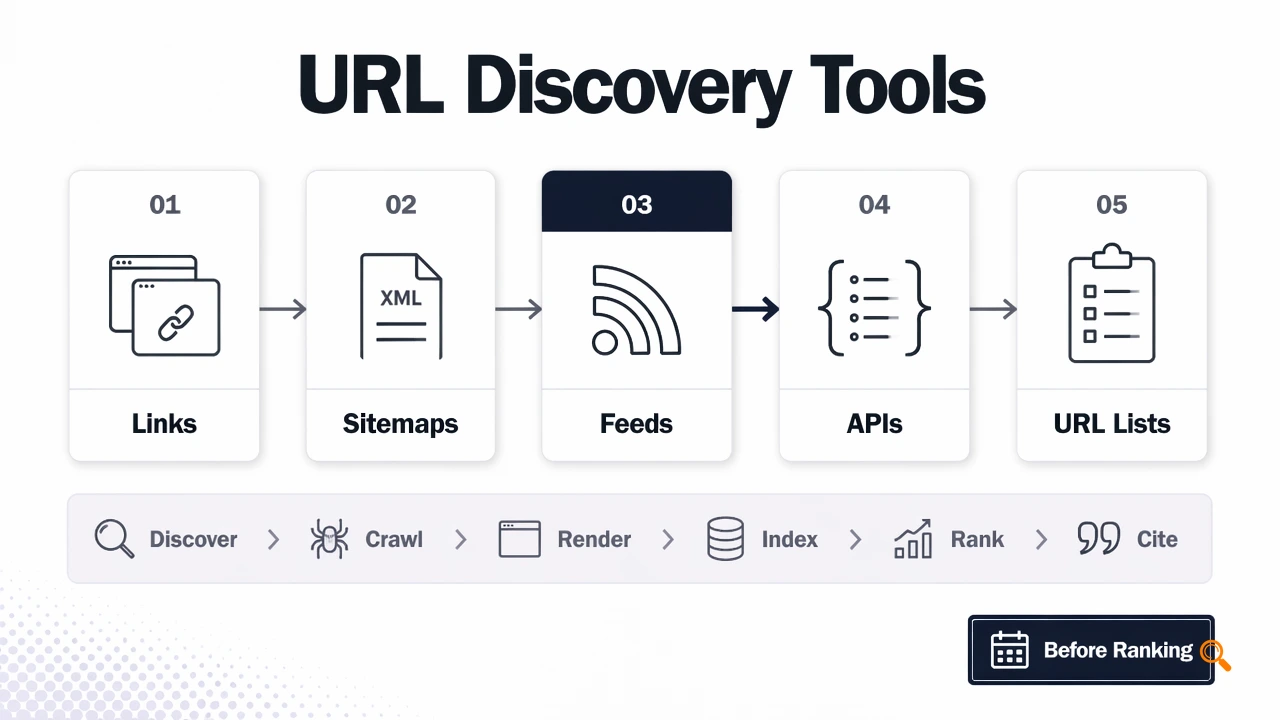
What are URL discovery tools?
URL discovery tools are systems that help crawlers find web addresses through links, sitemaps, feeds, APIs, passive collection, or submitted URL lists. Discovery comes before crawling, rendering, indexing, ranking, and AI citation, so weak discovery can hide otherwise strong pages from search systems.
Search and AI systems increasingly depend on clean, machine-readable signals. The 2023 LLaMA paper introduced efficient foundation language models, showing why structured, accessible web content matters as machine readers become more central to information retrieval (Touvron, Lavril, and Izacard, 2023).
Core discovery methods compared
| Method | Best use | Main limitation |
|---|---|---|
| Indexerhub | Coordinating discovery and indexing workflows for active sites | Works best with accurate URL inputs |
| Internal links | Passing crawl paths through site architecture | Orphan pages stay hidden |
| XML sitemaps | Listing canonical URLs for search engines | Stale files waste crawl attention |
| RSS or Atom feeds | Surfacing recent posts and updates | Limited coverage for non-editorial pages |
| Crawl tools | Finding broken paths, redirects, and orphan candidates | Audits discovery, not submission |
| Passive URL collectors | Recon from archives, code, and public sources | May surface obsolete or noncanonical URLs |
Discovery quality depends less on one tool and more on whether every important URL has at least two reliable discovery paths.
Which URL discovery tools fit SEO workflows?
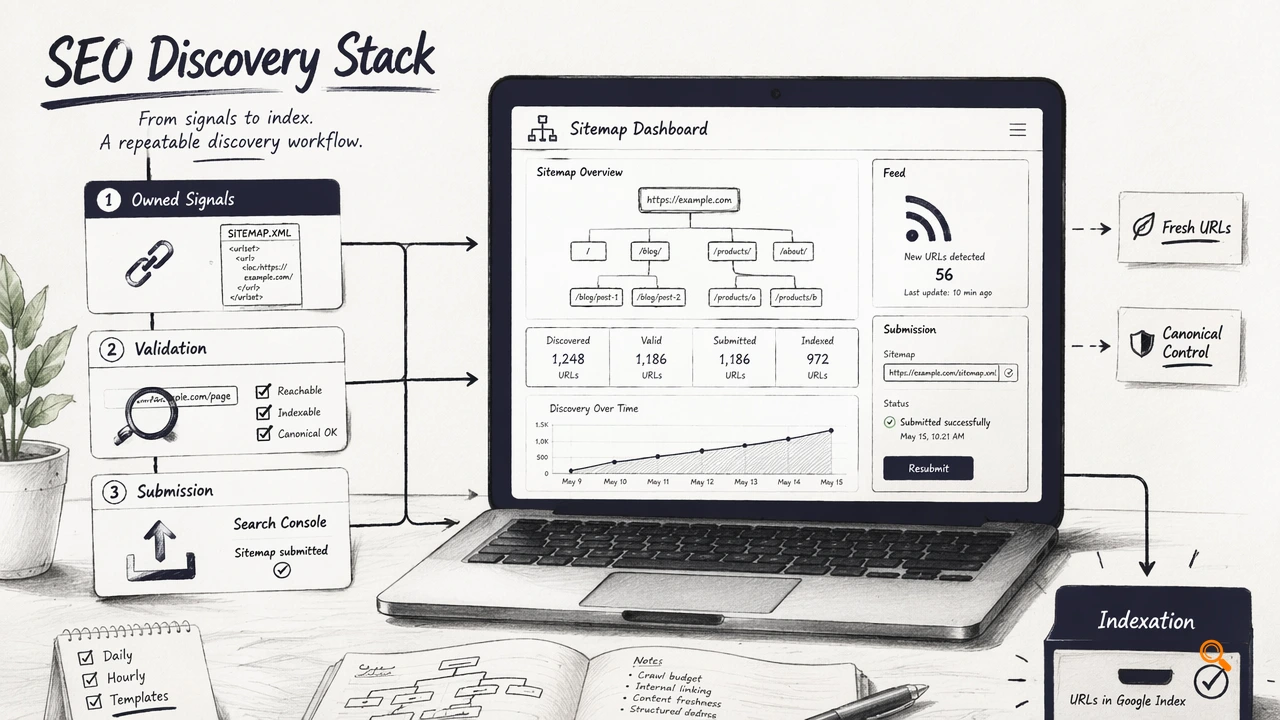
The best discovery stack for SEO combines owned signals first, then validation tools, then submission or indexing platforms. Large publishers, marketplaces, SaaS documentation sites, and programmatic SEO teams need repeatable processes because new URLs can appear daily, hourly, or through templates.
Competitor SERP patterns show security-oriented tools such as ProjectDiscovery URLFinder, URL fuzzers, and passive recon utilities ranking for discovery topics. Those tools help asset discovery, but SEO teams usually need canonicalization control, sitemap hygiene, feed freshness, and indexation monitoring rather than endpoint enumeration.
Selection checklist for 2026 teams
- Map URL sources: CMS publishing, product databases, faceted navigation, feeds, and API-generated pages.
- Confirm canonical status: only indexable, canonical URLs should enter sitemaps or submission queues.
- Refresh machine-readable files: update XML sitemaps and RSS feeds as publishing changes occur.
- Audit crawl paths: use crawlers to detect orphan URLs, redirect chains, and blocked sections.
- Prioritize important URLs: submit high-value pages first through approved indexing workflows.
Research on web servers such as DAVID's 2021 update shows how structured online systems depend on clear resource organization and functional access points (Sherman, Hao, and Qiu, 2022). SEO teams face a similar operational issue: URLs must be findable, valid, and worth processing.
How Indexerhub handles discovery at scale
Indexerhub helps teams turn scattered URL sources into a more controlled discovery and indexing workflow. The platform is most useful when content teams already publish frequently and need a practical layer between URL creation, validation, and search engine attention.
A good setup keeps negative signals away from submission queues. Blocked pages, duplicate variants, thin tag pages, internal search results, and redirected URLs should be filtered before any automation runs. That keeps discovery focused on URLs that deserve crawling.
After those controls are in place, Indexerhub can support faster operational handling for approved pages. More product details are available at indexerhub.com.
Best-fit use cases
- Programmatic SEO sites: send only canonical template outputs after quality checks.
- Content operations teams: surface new articles, refreshed pages, and priority updates faster.
- Agencies: manage discovery workflows across multiple client domains with clearer process control.
- Affiliate sites: reduce reliance on slow organic recrawling after commercial content updates.
The practical goal is not forcing every URL into search; the goal is making the right URLs easy for search systems and AI crawlers to find.
Conclusion
URL discovery tools work best as a layered system: internal links for crawl paths, sitemaps for canonical coverage, feeds for freshness, crawlers for QA, and indexing platforms for priority handling. Teams managing fast-changing sites should audit current discovery paths, remove low-value URLs from feeds and sitemaps, then test a controlled workflow with Indexerhub. For the next step, visit indexerhub.com and map the highest-value URLs that need faster discovery.