Robots.txt Blocking Indexing: What It Really Means

TL;DR
Robots.txt controls crawler access, but it does not reliably remove a URL from search results. The practical fix is to diagnose crawl blocks, confirm index status, add the right indexing directive, and validate changes with live tests, sitemaps, and logs.
Robots.txt blocking indexing is a common misunderstanding: the file can stop crawling, but a linked URL may still appear in search. Robots.txt: the Robots Exclusion Protocol is a standard that tells web crawlers which site areas they may visit. For large sites, Indexerhub helps teams keep indexing checks and crawl signals organized.
Table of Contents
What robots.txt actually controls
Robots.txt controls crawler access, not guaranteed index removal. Google's own robots.txt introduction explains that a disallowed page can still be indexed when other pages link to it, although Google should not crawl its content.

A Disallow rule blocks fetching. A noindex directive controls index inclusion, but search engines must crawl the page to see it. That difference matters for ecommerce filters, staging folders, faceted URLs, and programmatic pages.
Crawl control vs index control
| Signal | Main job | Best use | Risk |
|---|---|---|---|
robots.txt Disallow |
Blocks crawling | Save crawl budget or hide low-value paths from bots | URL can still be indexed from links |
meta robots noindex |
Blocks indexing | Remove accessible HTML pages from search | Fails if crawling is blocked |
X-Robots-Tag |
Blocks indexing for files or headers | PDFs, feeds, generated files | Needs correct server headers |
| Canonical tag | Consolidates duplicates | Similar product or article URLs | Not a removal command |
Key insight: robots.txt is a traffic gate for crawlers, not a deletion request for search indexes.
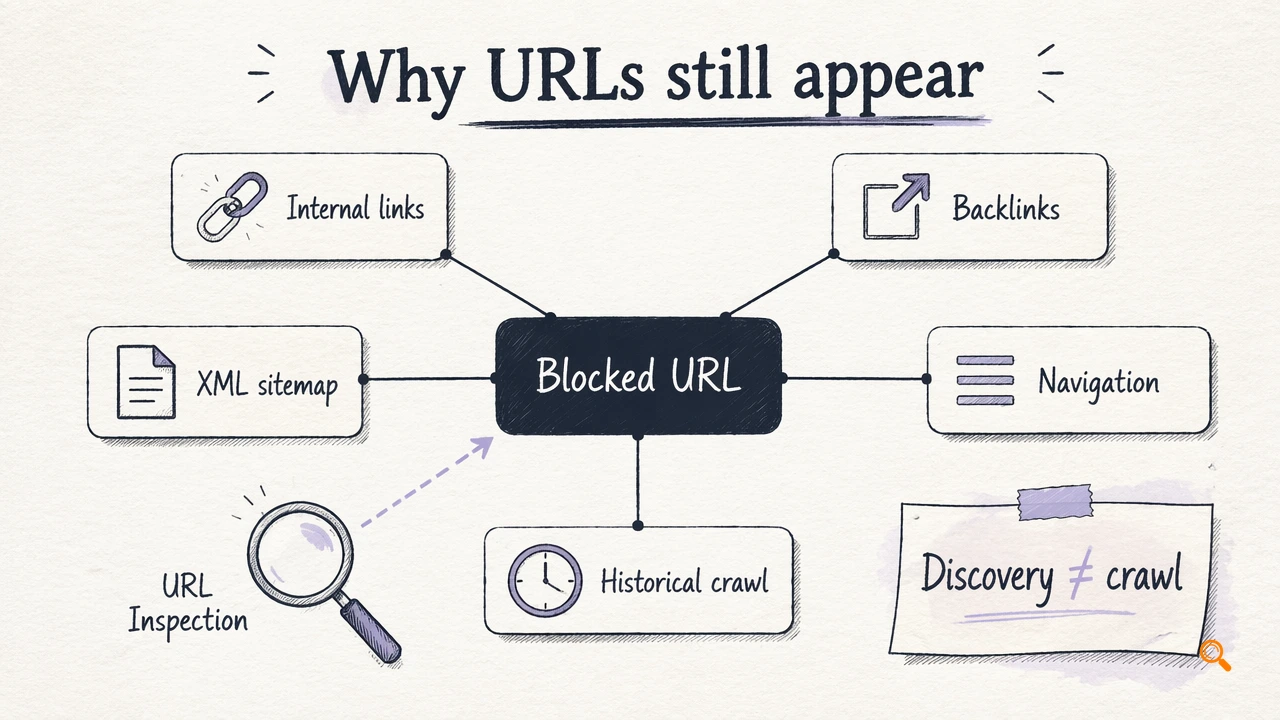
Why blocked URLs still appear in search
Blocked URLs still appear when search engines discover them without crawling their content. Discovery can happen through internal links, backlinks, XML sitemaps, navigation, canonicals, JavaScript-rendered links, or historical crawl data.
Research on crawler systems supports treating crawler behavior as a separate technical layer. Bergman and Popov's 2023 IEEE Access review, Exploring Dark Web Crawlers, examined crawler implementation patterns. Lentzsch, Shah, and Andow's 2021 NDSS paper on the Alexa Skill system also shows why automated discovery systems need precise access rules.
Common causes and correct response
- URL is blocked but linked: remove the block, add
noindex, allow recrawl, then block only if crawl saving still matters. - URL is in an XML sitemap: remove non-indexable URLs from the sitemap before resubmission.
- URL has backlinks: expect a placeholder result unless a crawlable removal signal exists.
- URL should rank: update robots.txt to allow the path, then request validation in Google Search Console.
Google's URL Inspection documentation remains the practical place to confirm whether Google sees a live block, a cached block, or an indexable page.
How to diagnose robots.txt indexing conflicts
A reliable diagnosis checks the rule, the live fetch, the sitemap, and the server record before changing anything. Guessing from the Search Console label alone can cause the wrong fix, especially on sites with templates, CDN rules, or multiple user-agent sections.
The Indexerhub platform fits teams that need repeatable checks across many URLs, because index monitoring works best when robots rules, sitemap inclusion, and inspection outcomes are reviewed together.
Five-step diagnostic sequence
- Check robots.txt directly: open
/robots.txtand confirm the exact path, wildcard, and user-agent rule. - Run URL Inspection: compare indexed status with crawl permission for the submitted URL.
- Run a live test: confirm the current rule, not only Google's last cached view.
- Audit XML sitemaps: remove blocked, redirected, canonicalized, or
noindexURLs from indexation sitemaps. - Review server logs: confirm whether Googlebot, Bingbot, or AI crawlers received
200,3xx,4xx, or blocked responses.
Practical rule: if a page needs removal, make it crawlable long enough for search engines to see
noindex; if it needs crawl-budget control only, keep the robots rule and accept that URL discovery may still occur.
Conclusion
Robots.txt blocking indexing should be treated as a signal conflict, not a single-file problem. The next step is to map every affected URL to its intended state: crawlable and indexable, crawlable and noindex, or blocked from crawling. For scaled monitoring, Indexerhub and indexerhub.com can support a cleaner indexing workflow.