Request Indexing in Google Search Console: Limits, Outcomes, and Workflow

TL;DR
Manual indexing requests help Google discover or revisit a URL, but they do not guarantee indexing or rankings. Large sites need eligibility checks, crawl signals, monitoring, and a repeatable workflow beyond one-off URL submissions.
Manual indexing requests are useful, but they are not an indexing strategy. Request indexing in Google Search Console sends one inspected URL into Google's recrawl queue after a quick live test; it does not guarantee crawling, indexing, or ranking. Request indexing: a Search Console URL Inspection action that asks Google Search to recrawl an eligible URL. For teams publishing at scale, Indexerhub can help turn one-off submissions into a trackable indexing workflow.
Table of Contents
What does request indexing in Google Search Console do?
Request indexing in Google Search Console asks Google to recrawl a specific URL after the URL Inspection tool checks that the page can be accessed. Google's official guidance says the tool reports crawl, index, and serving information from the Google index, while the request action only submits an eligible URL for consideration through URL Inspection.
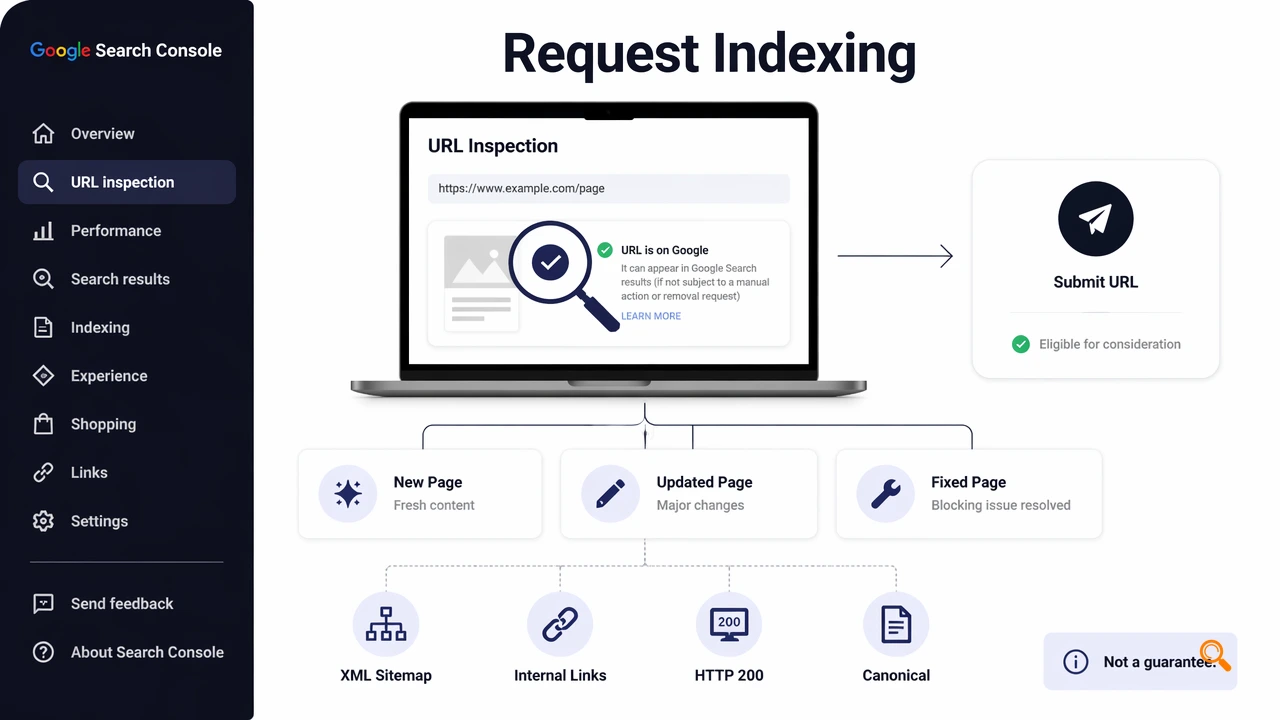
The action works best for newly published pages, substantially updated pages, or fixed pages that previously had blocking issues. It is not a replacement for XML sitemaps, internal links, clean HTTP responses, or canonical consistency.
Key insight: the button is a signal to Google, not a command to index a page.
Manual request versus stronger crawl signals
| Signal | Role in indexing | Best use |
|---|---|---|
| URL Inspection request | Asks Google to recrawl one URL | Urgent new or updated pages |
| XML sitemap | Lists canonical URLs for discovery | Large publishing systems |
| Internal links | Shows importance and relationship | Hubs, categories, related content |
| HTTP status and canonicals | Confirms eligibility | Technical validation before submission |
Google's documentation on asking Google to recrawl URLs also points to sitemaps for larger sets of pages through recrawl guidance.
Why is manual submission not enough?
Manual submission is not enough because indexing depends on eligibility, crawl demand, content quality, duplication, internal linking, and Google's own systems. A submitted page can remain unindexed if it is blocked by robots.txt, marked noindex, canonicalized elsewhere, thin, duplicate, orphaned, or returning an unreliable HTTP status.
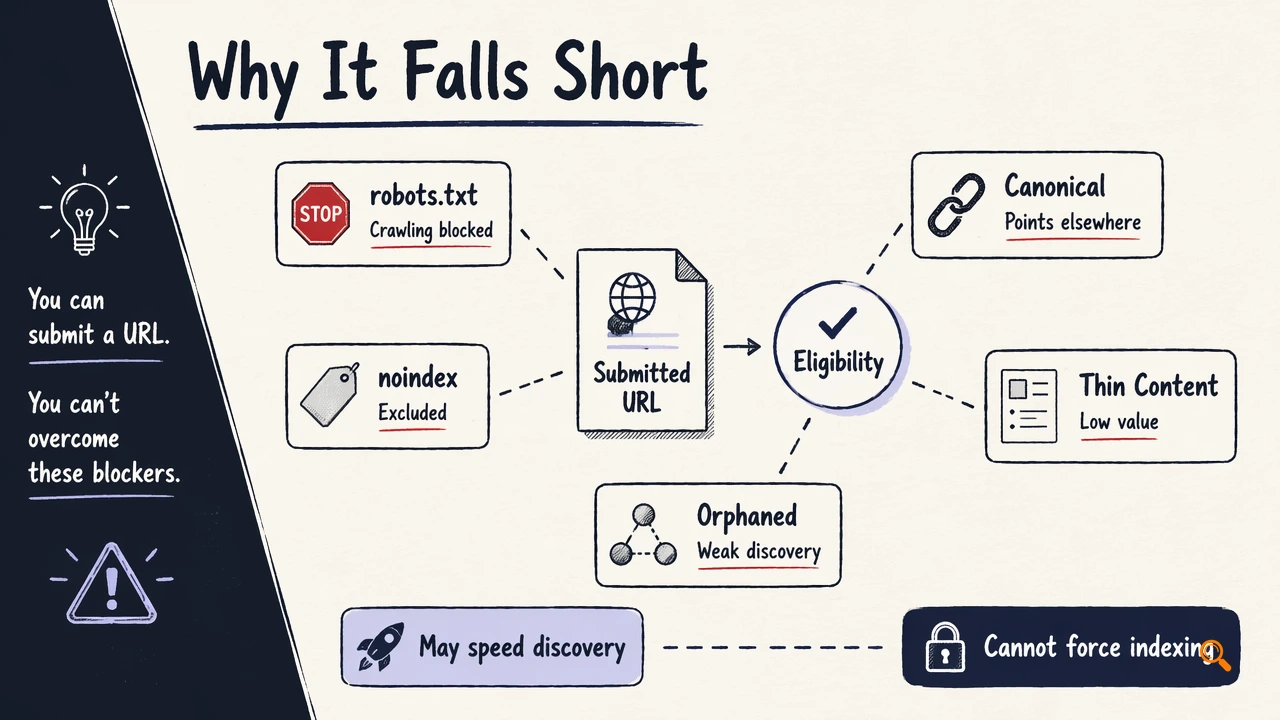
The practical expectation in 2026 is simple: the request may speed up discovery for a valid URL, but it cannot override weak site architecture or low page value. Search engine optimization, as defined in research summaries, focuses on improving visibility and performance in search results, not merely submitting URLs.
Key insight: indexing starts with discoverability, but lasting visibility depends on relevance, quality, and crawl efficiency.
Common outcomes after a request
- Indexed quickly: the URL is eligible, discoverable, and valuable enough to enter the index.
- Crawled but not indexed: Google saw the page but did not select it for the index.
- Discovered but delayed: Google knows the URL exists, but crawl scheduling has not caught up.
- Rejected by inspection: the live test finds a crawl, indexability, or access issue.
- Indexed under another URL: canonical signals point Google to a different version.
For AI-search visibility, indexation also needs clean, trustworthy source structure. Lund, Wang, and Mannuru's 2023 work on AI-written research and publishing ethics highlights the wider need for transparent information practices in machine-mediated discovery: study PDF.
How should SEO teams build a repeatable indexing workflow?
SEO teams should treat indexing as a process: validate URLs before submission, strengthen discovery signals, monitor outcomes, and escalate patterns instead of repeatedly pressing the same button. This approach fits blogs, marketplaces, SaaS resource centers, affiliate sites, and programmatic SEO libraries with frequent publishing.
A repeatable workflow separates inspection, submission, and reporting. Technical publishing projects such as JBrowse 2 show how modular web systems can manage complex, frequently updated resources; that same modular principle is useful for indexing operations: Genome Biology paper.
The Indexerhub platform is built around that operational layer: tracking URL status, organizing submissions, and reducing manual Search Console checks for teams handling many pages. More product details are available at indexerhub.com.
Workflow checklist for 2026
- Confirm the URL returns
200 OKand is not blocked. - Check
noindex, canonical tags, redirects, and mobile accessibility. - Add the URL to the correct XML sitemap.
- Link from relevant hubs, categories, or related pages.
- Use URL Inspection for priority URLs.
- Track whether the outcome is indexed, crawled but not indexed, or excluded.
- Group failures by template, section, or domain pattern.
| Workflow stage | Owner | Success signal |
|---|---|---|
| Preflight checks | Technical SEO | Eligible live URL |
| Discovery support | Content and SEO | Sitemap plus internal links |
| Monitoring | SEO operations | Status trend by URL group |
Conclusion
Request indexing in Google Search Console is best used as a targeted prompt after technical eligibility and discovery signals are already in place. For a scalable next step, SEO teams should audit priority URL groups, fix recurring exclusion patterns, then standardize monitoring with Indexerhub and visit indexerhub.com for workflow support.