Google Request Indexing Limits: What SEOs Can Actually Control

TL;DR
Manual indexing requests are best treated as a limited escalation path, not an indexing strategy. High-value, changed, or time-sensitive URLs deserve priority, while routine discovery should rely on sitemaps, internal links, clean HTTP responses, and monitoring.
Google request indexing limits matter because Search Console is a constrained signal, not a publishing pipeline. Competitor SERP research reports that Search Console manual submissions are commonly capped at roughly 10 individual URL requests per day, while Google Indexing API quota data in the SERP shows a default daily quota of 200 that resets at midnight Pacific Time.
Table of Contents
What are Google request indexing limits?
Google request indexing limits are practical caps on how many URLs can be manually submitted for recrawling through Google Search Console or related indexing systems. The key operational point is simple: a request asks Google to recrawl a URL, but it does not force crawling, indexing, ranking, or retention in the index.
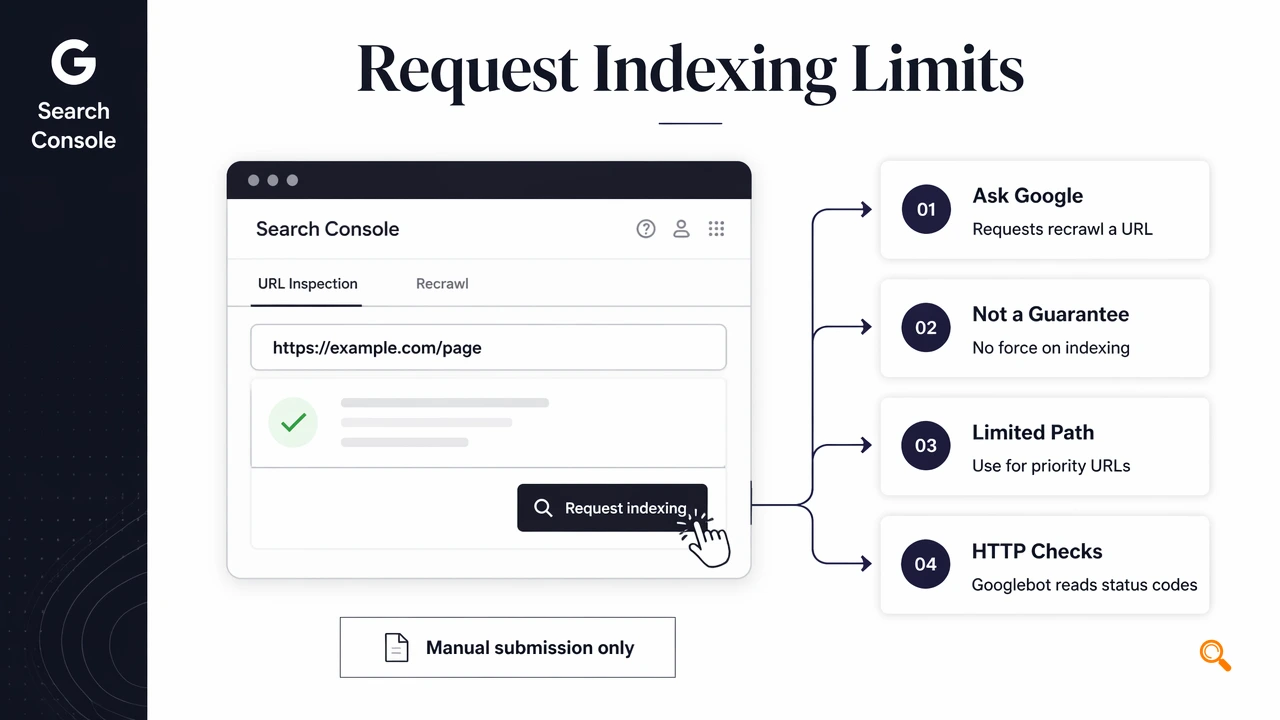
Request indexing: a manual Search Console action that asks Google to inspect and recrawl a specific URL.
HTTP: the application layer protocol that underpins data communication on the World Wide Web, including the status codes Googlebot reads when crawling pages.
Manual submission should be reserved for URLs where faster recrawling has clear business value.
Submission paths and practical limits
| Path | Reported limit signal | Best use |
|---|---|---|
| Search Console URL Inspection | About 10 individual requests per day in SERP competitor data | Critical new or updated pages |
| Google Indexing API | Default quota of 200 per day in SERP data | Eligible job posting and livestream-style use cases |
| XML sitemap discovery | No manual request count | Scaled discovery for normal publishing |
Search Console is built for diagnostics and selective escalation. Sitemaps and internal links remain the scalable discovery layer for large blogs, SaaS libraries, marketplaces, and programmatic SEO sites.
Why does a request not guarantee indexing?
A request does not guarantee indexing because Google still evaluates crawl access, canonical signals, duplication, quality, rendering, and index selection after the URL is submitted. Google data centers process search systems at scale, so a manual request enters a larger decision system rather than bypassing it.
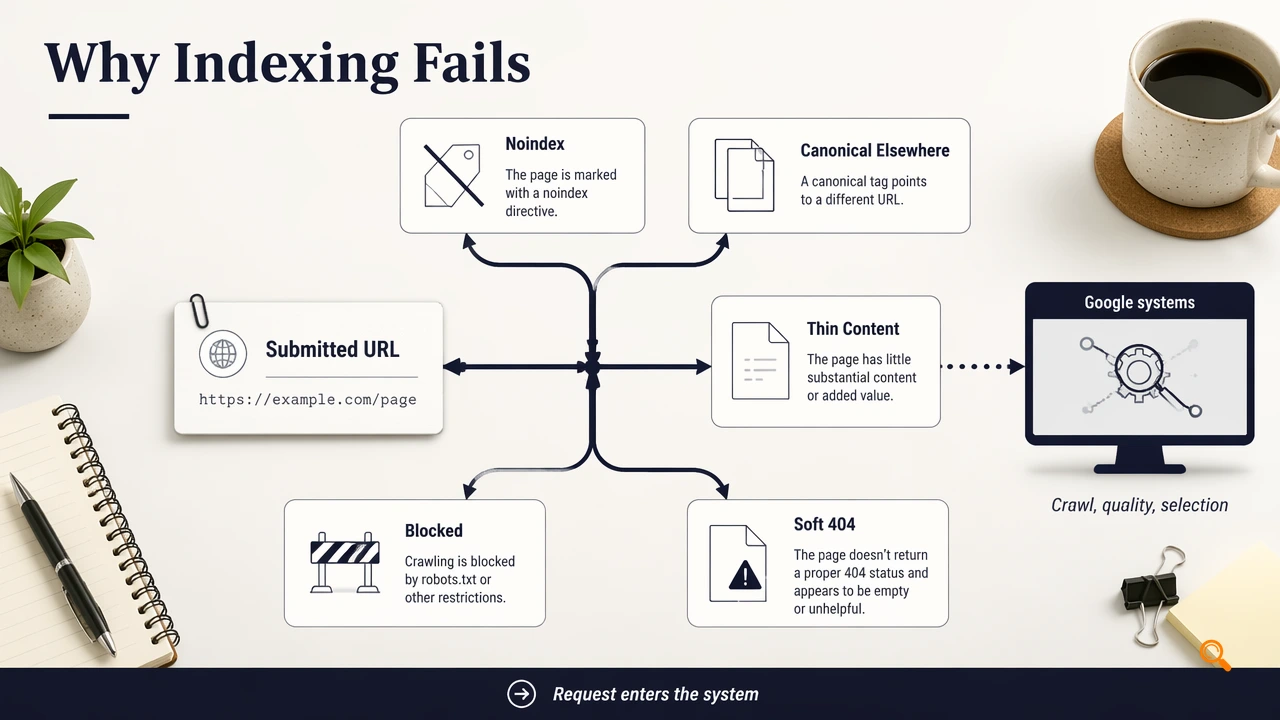
Common causes of a submitted URL staying unindexed include:
noindex, blocked resources, or server errors.- Weak internal links or orphaned page architecture.
- Duplicate content with another canonical URL.
- Thin pages that add little distinct value.
- Soft 404 behavior or unstable HTTP responses.
The strongest misconception is that repeated requests create priority. Re-submitting the same unchanged URL usually wastes quota and hides the real issue: Google may already have enough information to exclude the page.
Signals to verify before submitting
A clean request candidate should return a stable 200 HTTP status, be indexable, match the intended canonical, load primary content without blocking Googlebot, and appear in an XML sitemap or internal link path.
Research habits from systematic review methods are useful here. PRISMA 2020 guidance centers on explicit eligibility criteria, and SEO teams can apply the same idea by defining submission rules before spending manual requests.
If a URL fails basic eligibility checks, the indexing request is not the fix. The page, template, or crawl path needs correction first.
How should SEO teams prioritize manual requests?
SEO teams should prioritize manual requests for URLs where recrawling can change revenue, compliance, freshness, or search coverage quickly. Manual requests work best as a triage queue layered above automated monitoring, not as the default workflow for every published URL.
A practical 2026 workflow is:
- Detect new, changed, or excluded URLs through crawl and index monitoring.
- Filter out blocked, redirected, canonicalized, or low-value pages.
- Rank eligible URLs by business impact and freshness need.
- Submit only the highest-priority URLs manually.
- Track status changes before submitting again.
Indexerhub fits this workflow by helping teams monitor indexation patterns and focus attention on URLs that deserve action. The Indexerhub platform is most useful when manual requests are treated as the final step after technical validation.
Priority rules for large sites
| URL type | Manual request priority | Reason |
|---|---|---|
| Updated money page | High | Revenue impact and freshness matter |
| Corrected indexing error | High | A fixed blocker deserves recrawl attention |
| New evergreen blog post | Medium | Sitemap discovery may be enough |
| Programmatic long-tail page | Low | Scale favors templates and sitemaps |
Deep learning research reviews, such as Alzubaidi et al. in the Journal of Big Data, show how modern systems depend on pattern recognition at scale. For search visibility, that makes consistent technical signals more durable than one-off submission behavior.
For teams that need a repeatable queue, indexerhub.com is a practical place to start.
Conclusion
Google request indexing limits should push SEO teams toward discipline, not hacks. The next step is to audit indexable URLs, reserve manual submissions for high-impact pages, and use Indexerhub to turn indexing checks into a measured workflow rather than a daily guessing game.