Google AI Mode Citations Indexability: Technical SEO Guide

TL;DR
AI Mode citation work starts with indexability, not prompt-chasing. Pages need crawl access, index eligibility, clear answer blocks, fresh facts, and entity signals before citation tracking becomes meaningful.
Google AI Mode citations indexability starts before content quality: a page cannot be considered as a supporting link unless Google can crawl, render, index, and evaluate it. Indexerhub helps teams track that technical foundation at scale. Generative AI: artificial intelligence that uses generative models to produce text, images, code, audio, video, or other data. More operational detail is available at indexerhub.com.
Table of Contents
What makes a page eligible for AI Mode citations?
A page becomes eligible for AI Mode citation only after Google can access it, index it, and treat it as suitable for Search features. Google Search Central's AI features guidance, cited in the SERP research, states that supporting links in AI Overviews or AI Mode require indexed pages that are eligible to appear in Search.
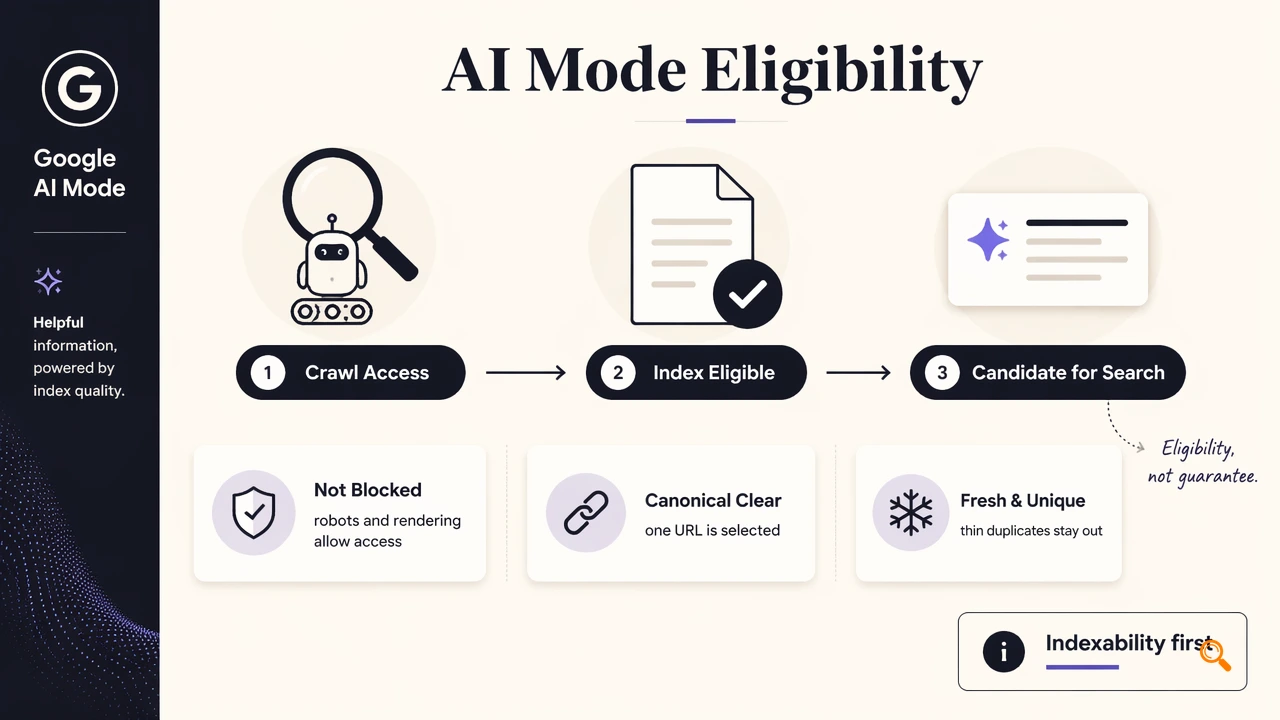
Indexability is not a citation guarantee. It is the technical entry ticket. Slow rendering, blocked resources, contradictory canonical tags, or thin duplicate URLs can keep strong content outside the candidate set.
Key insight: AI visibility should be measured only after crawl, render, canonical, and indexing checks pass.
Citation eligibility checklist
| Layer | What to verify | Why it matters |
|---|---|---|
| Crawl access | robots.txt, status codes, internal links |
Googlebot needs a reachable URL path |
| Renderability | JavaScript output, lazy content, blocked assets | AI systems need the final visible answer |
| Index signals | Canonical, noindex, sitemap inclusion |
Conflicting signals reduce eligibility |
| Search eligibility | Snippets, structured data, quality policy fit | AI Mode draws from Search-capable pages |
Large sites should test representative templates, not only homepage URLs. Programmatic SEO pages, faceted navigation, and marketplace listings often fail because templates multiply faster than crawl paths and canonical rules can support.
How should site architecture signal entities and answers?
Strong architecture helps AI systems connect pages to topics, entities, and factual claims. The 2021 ACM Computing Surveys paper Knowledge Graphs examines how structured entity relationships support machine-readable knowledge representation, which maps directly to modern SEO practices around schema, internal links, and consistent naming.
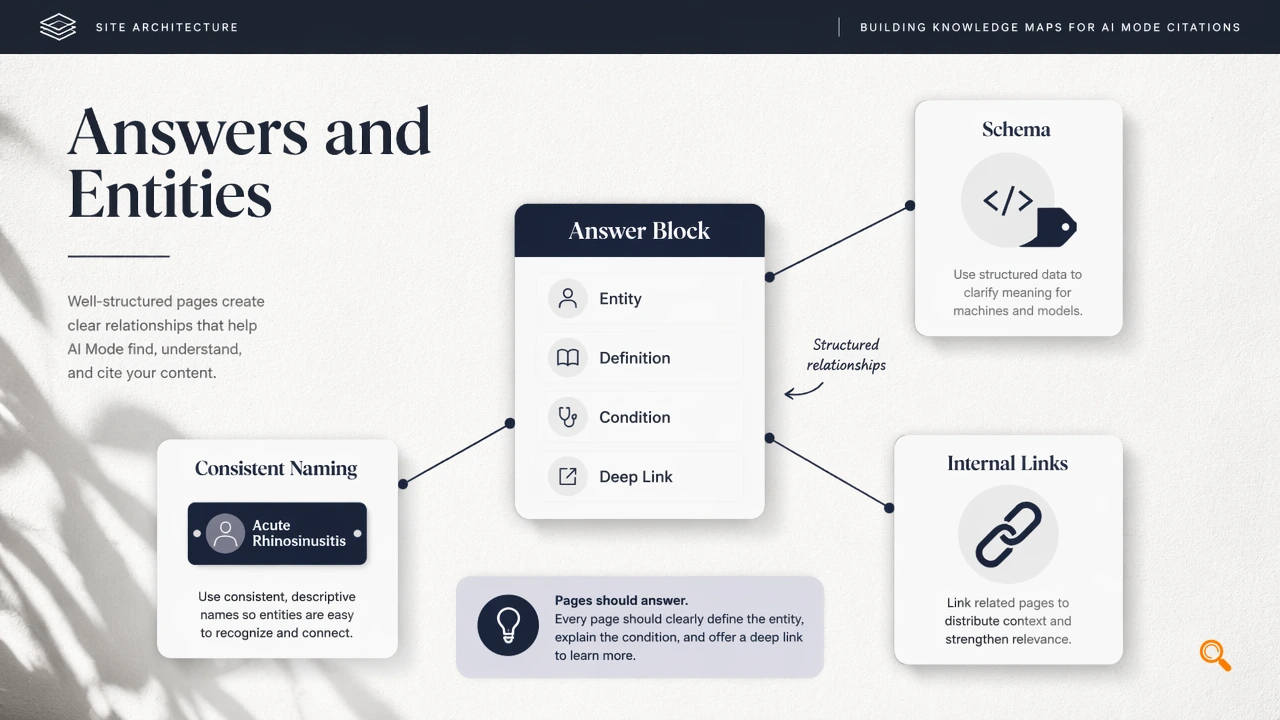
For citation eligibility, pages should not only rank; they should answer. A useful answer block names the entity, defines the concept, states the condition, and links to deeper supporting pages.
The 2026 survey of large language models reviews how LLMs process and generate language, reinforcing why clear entity context and factual density matter for extractable answers.
Architecture actions that help extraction
- Use one canonical URL per answer intent, especially across translated, filtered, or syndicated pages.
- Add definition blocks for core entities, products, standards, and categories.
- Connect hubs, comparisons, and support articles with descriptive anchors.
- Keep schema aligned with visible page content, not hidden assumptions.
- Refresh dates, facts, pricing, and availability when source content changes.
For publishing teams, Indexerhub fits best after content QA and before performance reporting. The platform can support indexation monitoring across many URLs while editors focus on clearer entity coverage and stronger answer formats.
What should be monitored in 2026 and 2027?
AI Mode monitoring should combine index coverage, organic visibility, citation presence, and freshness signals. SERP research for this topic found 19,100 competing results, while analyzed competitor articles averaged 3,588 words, which shows a crowded field where technical reliability can separate serious sites from generic AI-search advice.
Organic visibility still matters. Lily Ray analyzed 11 sites affected by Google's January 2026 update and reported that AI search citation losses closely followed organic declines: Google AI Mode fell 23.8%, ChatGPT fell 27.8%, and the average decline was 26.7%.
Citation tracking without index tracking can misread the cause. A missing citation may be a content issue, an authority issue, or a basic indexing issue.
Monitoring loop for faster diagnosis
- Check whether the URL is crawled and indexed.
- Confirm the canonical URL matches the intended page.
- Compare organic rankings with AI Mode citation presence.
- Review answer blocks for freshness, entity clarity, and source support.
- Re-submit or strengthen internal links after major updates.
By 2027, AI search reporting will likely move closer to standard SEO reporting: citation share, source diversity, and entity-level visibility will sit beside impressions and rankings. Sites with clean templates and current facts will be easier to diagnose.
Conclusion
Google AI Mode citations indexability is a controllable foundation, not a shortcut to guaranteed citations. The practical next step is a URL-level audit of crawl access, canonical signals, answer structure, entity clarity, and freshness, followed by recurring monitoring after every major content or template release.