Canonical Chains Indexing: How to Fix Signal Confusion

TL;DR
Canonical chains can make search engines choose the wrong indexed URL when canonical tags point through multiple hops or conflict with redirects, sitemaps, and internal links. Large sites should map variants, select one final canonical per content set, and validate the fix with crawls and indexing checks.
Canonical chains indexing problems often start quietly: one template points to a filtered URL, another points that URL somewhere else, and search engines must infer the final preferred page. Canonical chain: a sequence where URL A canonicals to URL B, which then canonicals to URL C instead of pointing directly to the final version.
Table of Contents
What is a canonical chain?
A canonical chain is an indirect canonical path that weakens the clarity of index selection because search engines receive more than one step before the preferred URL is reached. Google Search Central describes rel="canonical" as a way to indicate a preferred duplicate URL, not an absolute indexing command, in its guidance on consolidating duplicate URLs.

SERP research for this topic found 136 results and competitor pages averaging 2,448 words, yet many explanations stop at "avoid duplicate content." The harder issue is signal consistency across templates, parameters, pagination, hreflang, redirects, and XML sitemaps.
Canonical path examples
| Pattern | Example | Indexing risk |
|---|---|---|
| Clean canonical | A points to A | Strongest self-reference |
| One-hop duplicate | A points to B | Usually acceptable when B is final |
| Chain | A points to B, B points to C | Search engine must resolve intent |
| Loop | A points to B, B points to A | Conflicting preference signals |
| Mixed signals | A canonicals to B, sitemap lists A | Canonical and discovery disagree |
Key insight: canonical tags work best when every duplicate variant points directly to the same final indexable URL.
Why canonical chains disrupt indexing
Canonical chains disrupt indexing by making the preferred URL harder to confirm across crawl, render, and discovery signals. A search engine may still index the right page, but chained hints increase the chance that a parameter URL, redirected URL, or weaker duplicate remains selected.
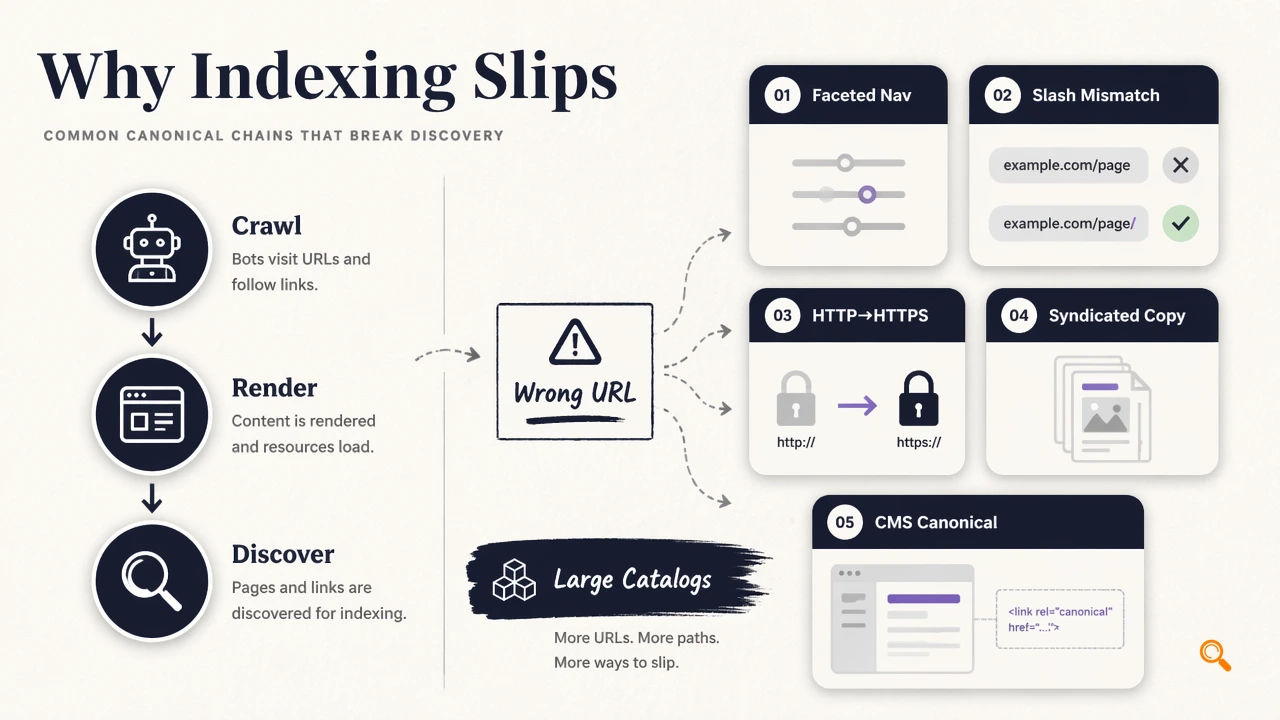
Common triggers include faceted navigation, trailing-slash mismatches, HTTP-to-HTTPS migrations, syndicated content, uppercase URL variants, and CMS templates that generate canonicals from the current request instead of the intended master URL. Large catalogs and programmatic SEO sites are most exposed because one template mistake can affect thousands of URLs.
Validation steps for large sites
- Crawl all indexable and non-indexable URL variants.
- Extract canonical targets from HTML and rendered HTML.
- Compare canonical targets with final status codes and redirects.
- Check whether XML sitemaps list only canonical URLs.
- Match internal links against the canonical destination.
- Review sampled URLs in Google Search Console's indexing reports.
A reliable audit separates three ideas:
- Declared canonical: the URL in the canonical tag.
- Final destination: the URL after redirects.
- Selected canonical: the URL search engines choose for indexing.
When those three differ, the site has a signal alignment problem rather than a simple tag problem.
How large sites should clean up canonical chains
Large sites should clean up canonical chains by choosing one final canonical per duplicate set, then forcing every related signal to support that URL directly. The safest rule is simple: duplicates, parameters, and alternate paths should point straight to the final canonical page, not through another duplicate.
For scaled publishing teams, the Indexerhub platform can support the post-cleanup workflow by helping teams focus indexing attention on validated canonical URLs after technical fixes are deployed.
Cleanup workflow for templates and variants
- Define the canonical rule at the template level, not page by page.
- Use absolute canonical URLs with the preferred protocol, host, path, and trailing-slash format.
- Keep sitemap URLs, internal links, hreflang return tags, and canonical tags aligned.
- Remove canonical targets that redirect, return errors, or are blocked by
robots.txt. - Re-crawl sample templates after release, then monitor fresh URLs.
Indexerhub fits best after validation, when a site has confirmed that selected pages are crawlable, indexable, and internally supported. Teams managing frequent launches can also visit indexerhub.com when ongoing indexing checks matter more than one-time audits.
Conclusion
Canonical chains indexing fixes are less about adding more tags and more about removing ambiguity. The next step is to crawl representative templates, map canonical paths, and update every duplicate variant so it points directly to the final indexable URL. After cleanup, ongoing monitoring should confirm that search engines select the intended canonical at scale.